Follow-Your-Shape (EditAnyShape): Shape-Aware Image Editing via Trajectory-Guided Region Control
ICLR 2026
* Equal contribution ✉ Corresponding author
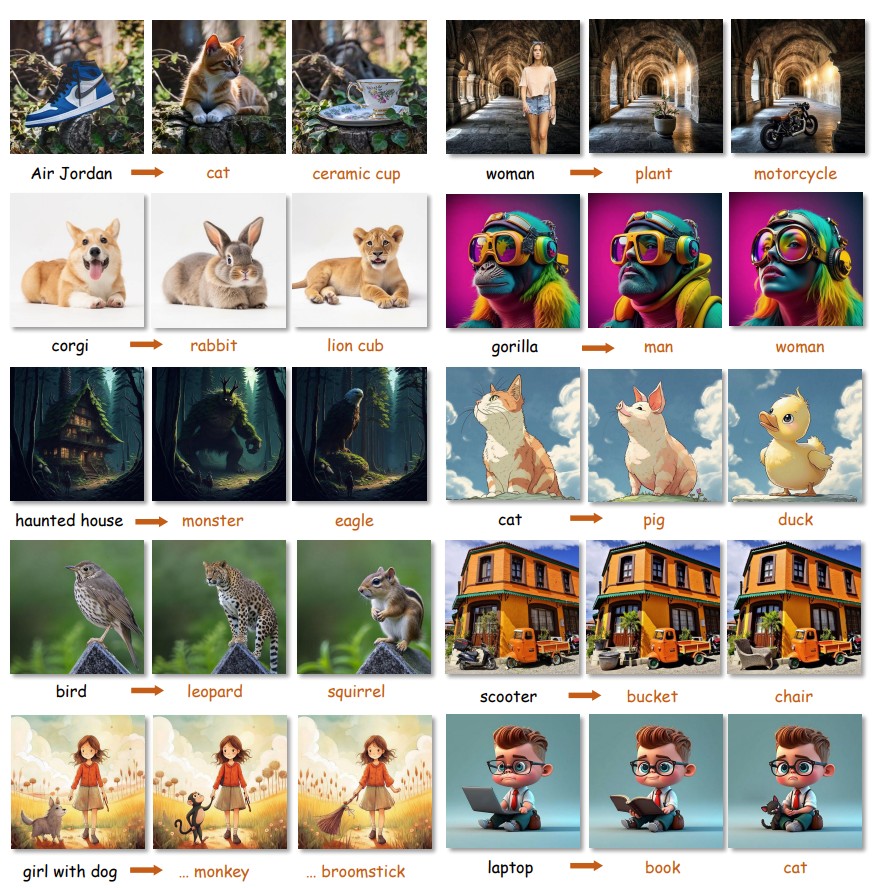
While recent flow-based image editing models demonstrate general-purpose capabilities across diverse tasks, they often struggle to specialize in challenging scenarios — particularly those involving large-scale shape transformations. When performing such structural edits, these methods either fail to achieve the intended shape change or inadvertently alter non-target regions, resulting in degraded background quality. We propose Follow-Your-Shape, a training-free and mask-free framework that supports precise and controllable editing of object shapes while strictly preserving non-target content. Motivated by the divergence between inversion and editing trajectories, we compute a Trajectory Divergence Map (TDM) by comparing token-wise velocity differences between the inversion and denoising paths. The TDM enables precise localization of editable regions and guides a Scheduled KV Injection mechanism that ensures stable and faithful editing. To facilitate a rigorous evaluation, we introduce ReShapeBench, a new benchmark comprising 120 new images and enriched prompt pairs specifically curated for shape-aware editing. Experiments demonstrate that our method achieves superior editability and visual fidelity, particularly in tasks requiring large-scale shape replacement.
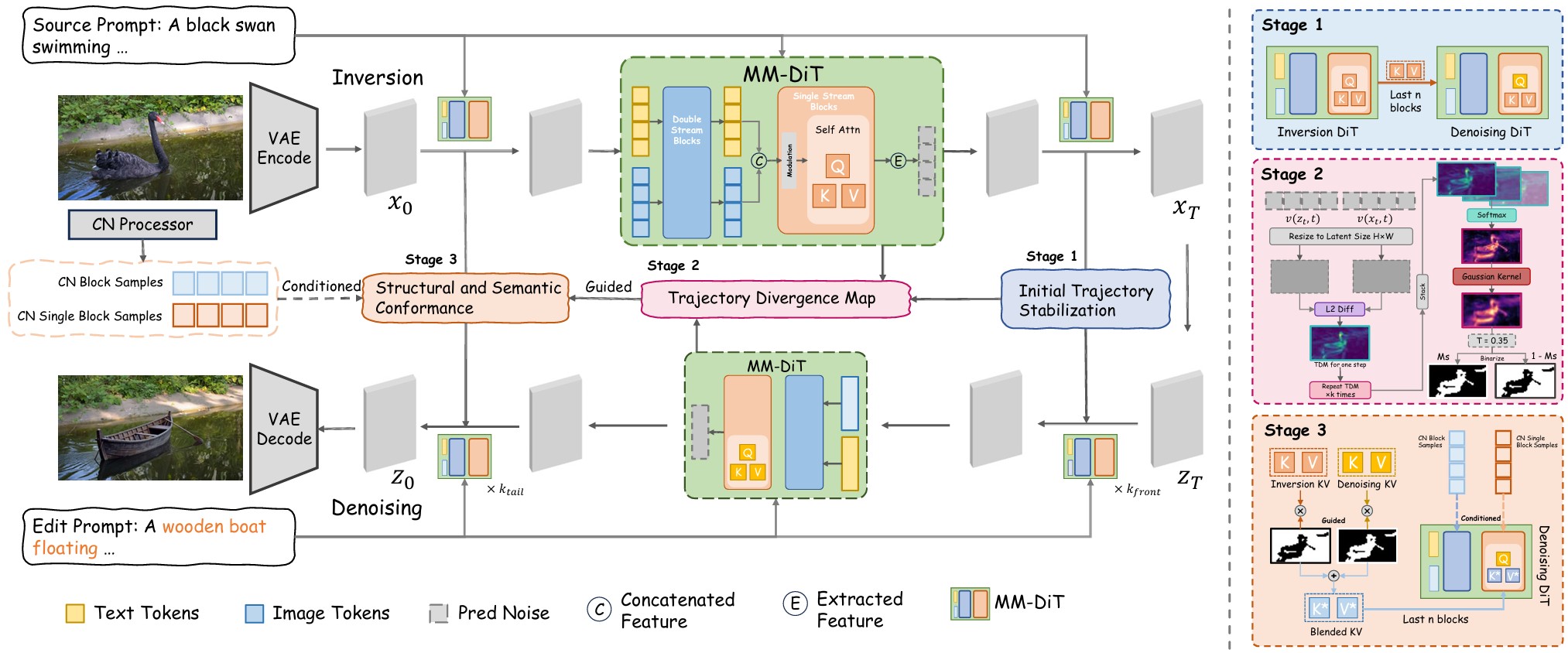
The editing process is divided into three stages. In Stage 1, we stabilize the initial denoising trajectory by injecting key-value (KV) features from the inversion path into the denoising model during its initial steps. In Stage 2, we compute a Trajectory Divergence Map (TDM) by comparing the denoising trajectories generated from the source and edit prompts, and process this map to precisely identify the regions intended for editing. In Stage 3, we perform the final edit: guided by the TDM, blended KV features are injected into the final attention blocks of the denoising model to introduce the new semantics, while ControlNet conditions are supplied to ensure the edited regions conform to the original structure.



@inproceedings{
long2026followyourshape,
title={Follow-Your-Shape: Shape-Aware Image Editing via Trajectory-Guided Region Control},
author={Zeqian Long and Mingzhe Zheng and Kunyu Feng and Xinhua Zhang and Hongyu Liu and Harry Yang and Linfeng Zhang and Qifeng Chen and Yue Ma},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=uGaR7L3Z1E}
}